H100 from $0.65/hr, H200 from $2.25/hr, B200 from $3.75/hr. No contracts, no spot/reserved maze, no vendor lock-in. Here’s what packet.ai is and how it works.
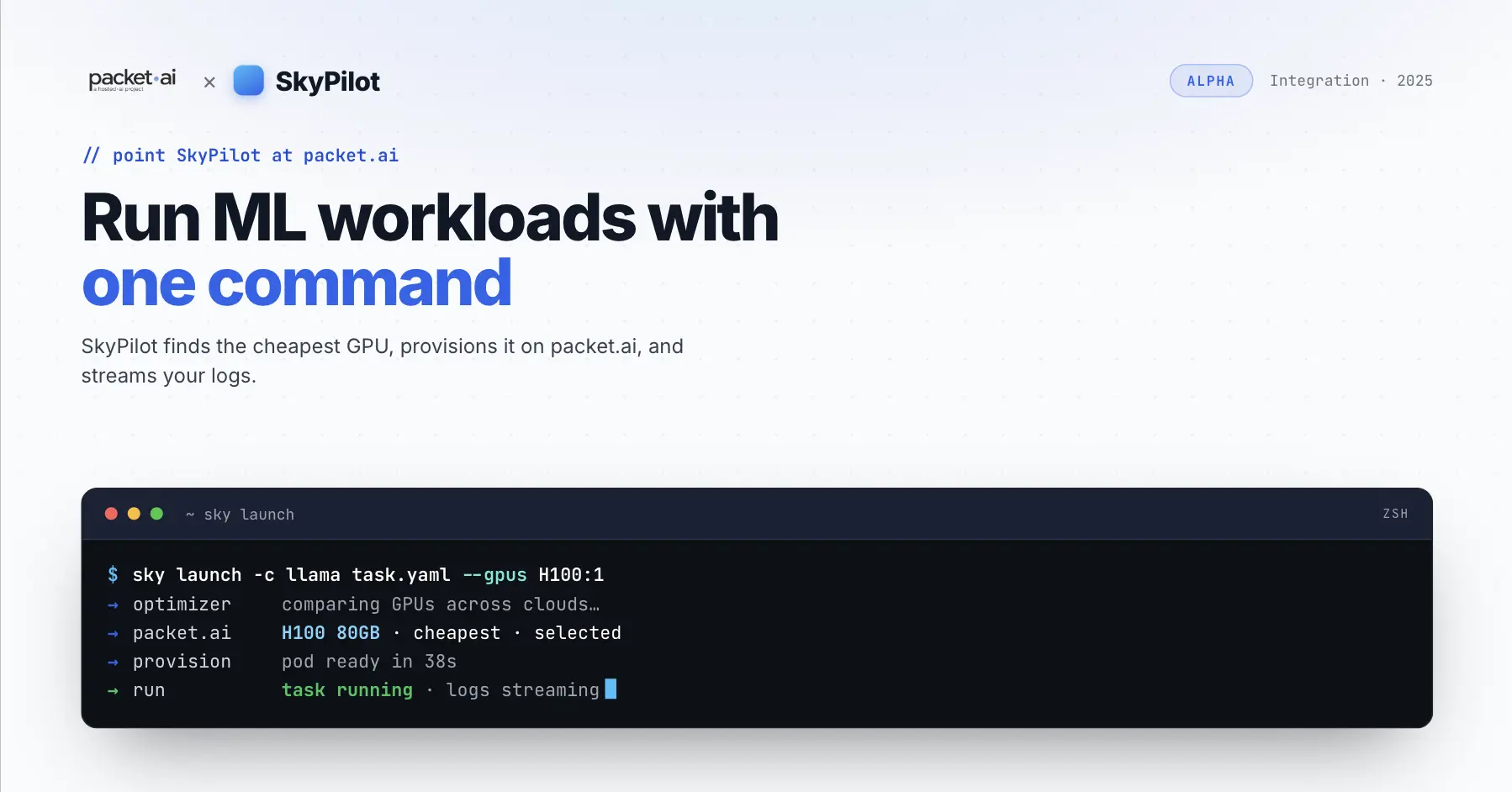
packet.ai gives AI/ML teams access to high-end GPU compute from a single platform — H100, H200, B200, and RTX PRO 6000 Blackwell — at transparent hourly prices with no contracts, no negotiation, and no vendor lock-in.
Key takeaways
packet.ai was built for teams that need serious GPU compute without the usual friction. If you’re training, fine-tuning, or running inference on models that don’t fit neatly into hyperscaler pricing or long-term commitments, this is the platform.
Most GPU platforms fall into one of two categories: hyperscaler complexity (AWS, GCP — powerful but expensive and over-engineered for most AI workloads) or marketplace chaos (random providers, inconsistent quality, unclear accountability).
packet.ai is neither. Every GPU on packet.ai runs on infrastructure powered by hosted·ai — not random providers aggregated from a spreadsheet. One interface. Consistent experience. Accountable support. When something goes wrong, we own the problem because we understand the infrastructure end-to-end.
No spot vs reserved vs on-demand maze. No opaque discounts. No enterprise negotiation. You pick a GPU, you see the hourly price, you pay for what you use.
packet.ai also offers reserved pricing for teams with predictable steady-state GPU needs — reserved contracts typically deliver 20–40% discounts versus on-demand for 1–3 month commitments. The break-even sits at around 65% utilisation for H200 and B200 — if your GPU will run at more than that, reserved is worth it. See the GPU pricing models guide for the full break-even analysis.
packet.ai is more than GPU-hours. The platform includes: one-click dev environments (VS Code in browser, Jupyter Lab, Jupyter + PyTorch); persistent workspaces so your environment survives pod restarts; the Token Factory inference API at $0.10/M tokens; and the SM Activity dashboard that shows whether your GPU is actually computing or just appearing busy.
These aren’t add-ons. They’re part of what makes the platform usable as a daily driver for ML engineering, not just a raw compute source. Browse available clusters to see current GPU availability.
Last reviewed: 10 June 2026. Browse available GPU clusters on packet.ai →
Same models. Same API. Fraction of the cost. Start free — no credit card required.
Start Building →