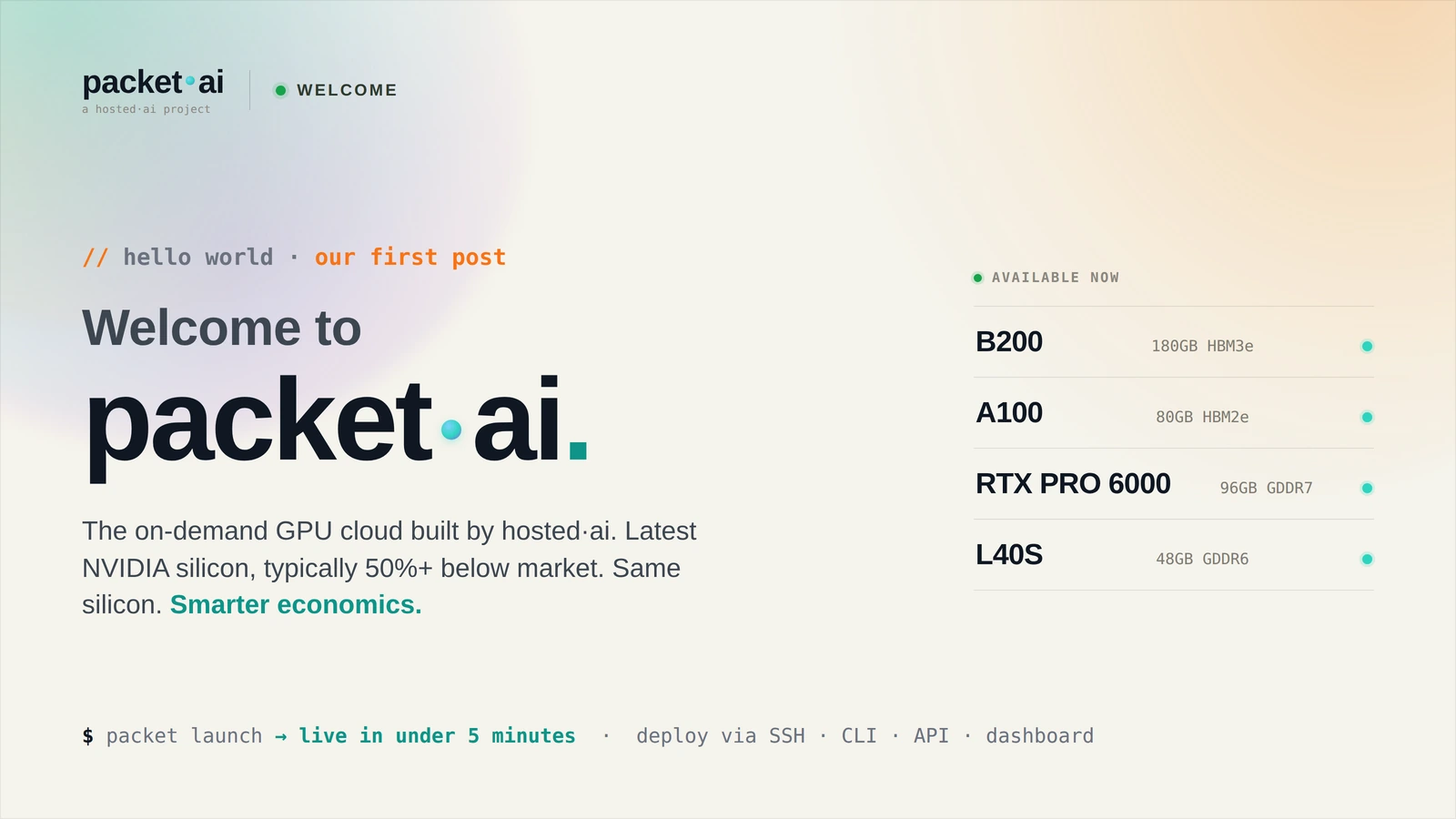
$0.10/M tokens for Llama, Qwen, DeepSeek — same OpenAI SDK, one line change. Here's why Token Factory exists and what it costs vs GPT-4o.
Token Factory is packet.ai's OpenAI-compatible managed inference API at $0.10/M tokens — the same models, same SDK, same streaming, but 98% cheaper than GPT-4o for the 80% of production use cases where Llama or Qwen is good enough.
Key takeaways
base_url in your existing OpenAI SDK setupDeveloper after developer came to packet.ai with the same story: inference costs that started manageable and scaled to threatening. Token Factory is the answer.
The pattern is consistent across AI product teams. Early stage: OpenAI free tier, everything works. Growing: $500/month, still manageable. Scaling: $5,000/month, starting to hurt. Successful: $50,000/month, now it's a line item that threatens the business model.
At that point the math stops making sense. Some teams tried solving it by self-hosting inference — setting up vLLM, configuring load balancing, handling CUDA driver issues, managing autoscaling. It worked, but they'd traded a cost problem for a DevOps problem with a fully loaded engineering cost that often exceeded the inference bill.
The core insight
For most production use cases — RAG pipelines, classification, summarisation, code generation, customer support — open-source models match GPT-3.5 quality. You shouldn't pay enterprise margins for proprietary model infrastructure when the open-source alternative is good enough.
The 100M token/month comparison is not theoretical. That's a mid-sized SaaS product running a RAG pipeline with 20 queries per active user per day at ~5,000 users. On GPT-4o that's $75,000/year in inference alone. On Token Factory it's $120/year.
Token Factory is OpenAI-compatible. There is no new SDK to install, no new response format to parse, no streaming implementation to rewrite.
from openai import OpenAI
# Before
client = OpenAI(api_key="sk-...")
# After — one line change
client = OpenAI(
base_url="https://dash.packet.ai/api/v1",
api_key="your-packet-api-key"
)
response = client.chat.completions.create(
model="meta-llama/Llama-3.3-70B-Instruct",
messages=[{"role": "user", "content": "Hello"}],
stream=True # streaming works too
)LangChain, LlamaIndex, the JavaScript SDK, structured output — all supported. Same response shape as OpenAI.
Token Factory is not replacing GPT-4 for complex multi-step reasoning tasks. For agentic workflows requiring extended thinking, nuanced legal or medical analysis, or cutting-edge frontier capability, OpenAI and Anthropic's proprietary models remain the right call. But for the 80% of production volume — classification, summarisation, structured extraction, RAG retrieval responses, code generation at 7B–70B scale — the open-source models available through Token Factory are good enough, and charging $6,250/month for that workload is indefensible.
Last reviewed: 10 June 2026. Try Token Factory — first 10,000 tokens free →
Same models. Same API. Fraction of the cost. Start free — no credit card required.
Start Building →