GPU pod snapshots save configuration, not disk images. Here’s exactly what survives termination and how to architect persistent storage so you stop losing pip packages.
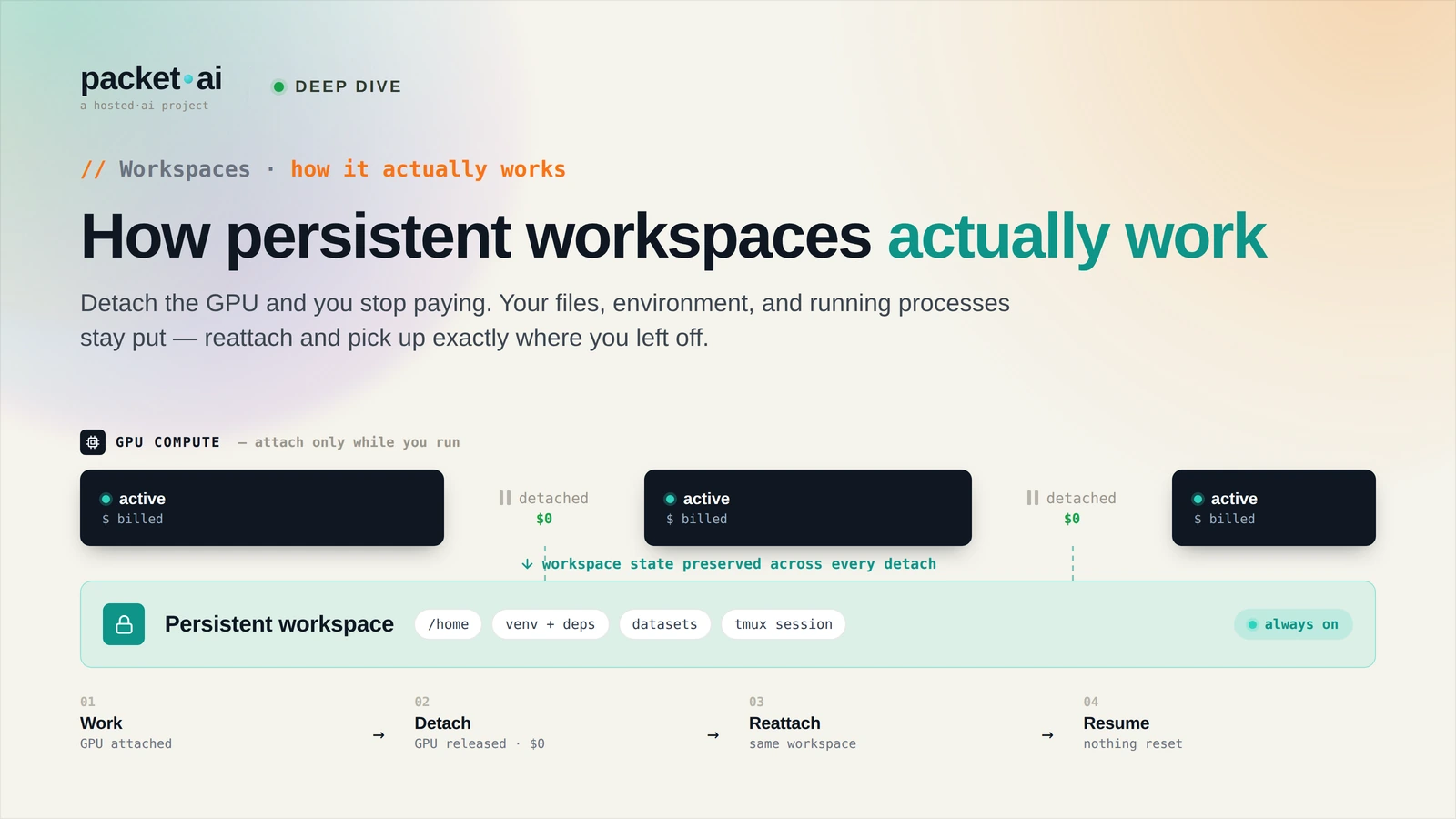
GPU pod snapshots on packet.ai save a configuration bookmark — not a disk image. Everything outside your mounted persistent volume is destroyed on pod termination, every time, without exception.
Key takeaways
/home/ubuntu, pip packages, running processes, and /tmp are all destroyed on pod termination/data/shareXX/ (NFS persistent volume) survives restarts — this is where models, datasets, and checkpoints must live/data/shareXX/pip-packages/ and loaded via PYTHONPATHIf you’ve ever terminated a GPU pod, created a snapshot, restored it, and lost your pip packages — this post is for you. The mental model of a snapshot as a VM image is wrong. Here’s what actually happens.
When most engineers hear “snapshot,” they think of a VM snapshot — a complete point-in-time image of the disk. That’s not what GPU pod snapshots are. Cloud GPU pods run in containers, and container infrastructure works fundamentally differently from VMs.
A container has a base image (the OS, CUDA drivers, base packages) and a runtime layer (anything you install or create after the container starts). The runtime layer is ephemeral by design. When the container stops, the runtime layer is discarded.
⚠ What is destroyed on every pod termination
/home/ubuntu and all its contents — pip packages, config files, scripts, SSH keys added at runtime, .bashrc modifications, /tmp — everything not mounted from a persistent volume is gone. No exceptions. No recovery.
LLM model weights — always on persistent storage, never re-downloaded per session:
# Set HuggingFace cache to persistent volume
export HF_HOME=/data/shareXX/huggingface
# Download once, reuse across pod restarts
huggingface-cli download meta-llama/Llama-3.3-70B-Instruct
python -c "from transformers import AutoModelForCausalLM; AutoModelForCausalLM.from_pretrained('meta-llama/Llama-3.1-8B')"Pip packages — persist to avoid reinstalling on every restart:
# Install to persistent volume
pip install --target=/data/shareXX/pip-packages torch transformers vllm
# Add to PATH on every session (add to .bashrc in /data/shareXX/)
export PYTHONPATH=/data/shareXX/pip-packages:$PYTHONPATH
# Or use a startup script on your pod
if [ -f /data/shareXX/requirements.txt ]; then
pip install -r /data/shareXX/requirements.txt
fiTraining checkpoints — always write to /data/shareXX/checkpoints/. If a pod is interrupted, your checkpoint is safe. Without this, a failed 8-hour training run means starting from scratch.
Packages gone after restart
Expected. pip installs to /home/ubuntu/.local/ by default, which is ephemeral. Fix: use pip install --target=/data/shareXX/pip-packages and set PYTHONPATH.
Storage still billing after pod deletion
Volumes exist independently of pods. Deleting a pod does not delete the volume. Go to the Storage tab and explicitly delete the volume when done.
Restore failed: volume not found
The volume was deleted, or it’s currently attached to another running pod. One volume can only be mounted to one pod at a time. Detach or terminate the other pod first.
Last reviewed: 10 June 2026. Browse GPU clusters on packet.ai →
Same models. Same API. Fraction of the cost. Start free — no credit card required.
Start Building →