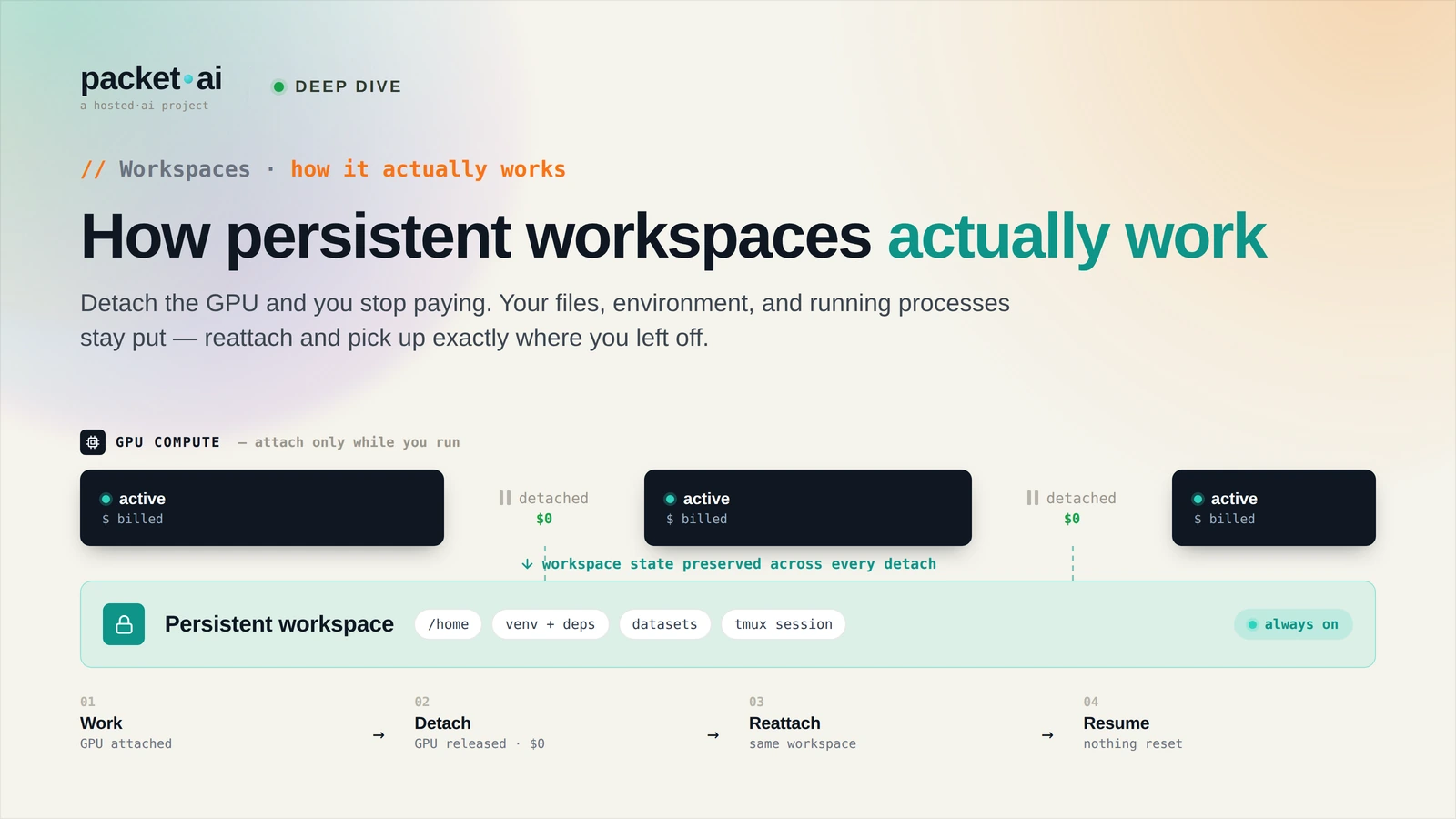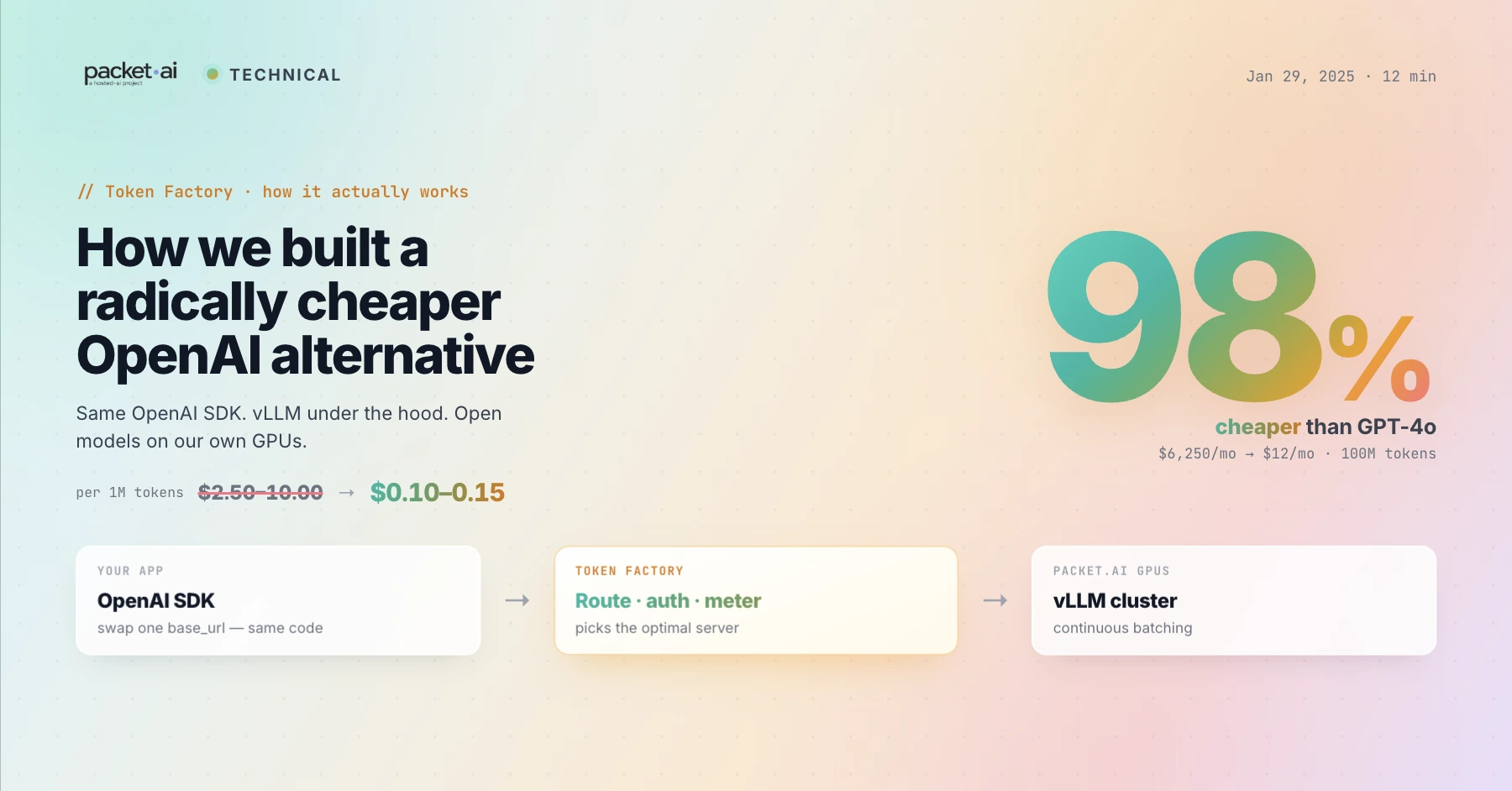
OpenAI-compatible, $0.10/M real-time, $0.05/M batch, LoRA fine-tuning from $5. Here's exactly how Token Factory works under the hood.
Token Factory is packet.ai's managed LLM inference API: OpenAI-compatible, $0.10/M tokens real-time and $0.05/M batch, with LoRA fine-tuning and no infrastructure to manage.
Key takeaways
base_url), keep existing SDK, streaming, and tool callingextra_bodyThis post covers the technical implementation of Token Factory: the API endpoints, batch processing workflow, LoRA fine-tuning API, and why the pricing works. For the background on why we built it, see Why We Built Token Factory.
Token Factory implements the OpenAI Chat Completions API spec. The migration is a single line:
from openai import OpenAI
client = OpenAI(
base_url="https://dash.packet.ai/api/v1",
api_key="your-packet-api-key"
)
# Streaming
stream = client.chat.completions.create(
model="meta-llama/Llama-3.3-70B-Instruct",
messages=[{"role": "user", "content": "Explain KV cache"}],
stream=True
)
for chunk in stream:
print(chunk.choices[0].delta.content or "", end="")
# With LangChain
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="meta-llama/Llama-3.3-70B-Instruct",
openai_api_base="https://dash.packet.ai/api/v1",
openai_api_key="your-packet-api-key"
)Tool calling, JSON mode, and structured outputs are supported on all models. Response format is identical to OpenAI — your existing parsing code works unchanged.
For offline workloads — dataset labelling, document summarisation, evaluation pipelines, nightly processing jobs — batch mode cuts the price by 50% versus real-time.
Batch workflow: prepare a JSONL file, POST it, poll for completion, download results:
# 1. Prepare requests.jsonl
# {"custom_id": "req-1", "method": "POST", "url": "/v1/chat/completions",
# "body": {"model": "meta-llama/Llama-3.3-70B-Instruct",
# "messages": [{"role": "user", "content": "Classify: {text}"}]}}
# 2. Submit batch
curl -X POST https://dash.packet.ai/api/v1/batch \
-H "Authorization: Bearer YOUR_API_KEY" \
-F "file=@requests.jsonl" \
-F "sla=24h"
# 3. Poll status
curl https://dash.packet.ai/api/v1/batch/{batch_id} \
-H "Authorization: Bearer YOUR_API_KEY"
# 4. Download results when complete
curl https://dash.packet.ai/api/v1/batch/{batch_id}/results \
-H "Authorization: Bearer YOUR_API_KEY" -o results.jsonlToken Factory supports LoRA adapter training directly via the API. No GPU provisioning, no infrastructure setup. Supply 50–500 high-quality examples, pick a base model, and get a deployed adapter in 10–60 minutes.
Typical cost: $5–50 per run depending on dataset size and model. The adapter is stored on packet.ai and served at inference time via a single extra_body parameter.
# Train a LoRA adapter
curl -X POST https://dash.packet.ai/api/dashboard/token-factory/lora \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"name": "support-classifier-v1",
"base_model": "meta-llama/Llama-3.3-70B-Instruct",
"training_data": "s3://your-bucket/train.jsonl",
"epochs": 3,
"rank": 16
}'
# Use the adapter at inference time
response = client.chat.completions.create(
model="meta-llama/Llama-3.3-70B-Instruct",
messages=[{"role": "user", "content": "Classify this ticket..."}],
extra_body={"lora_adapter": "lora_support_classifier_v1_abc123"}
)Three compounding reasons:
Open-source models with no margin stack
Llama 3.3 70B, Qwen 2.5 72B, and DeepSeek R1 are free to deploy. OpenAI's pricing includes model development cost recovery, proprietary API infrastructure margins, and enterprise support. None of those apply here.
vLLM continuous batching
vLLM's PagedAttention and continuous batching keep GPU utilisation high by dynamically grouping requests. This means the cost per token is spread across many concurrent requests rather than charged at dedicated-GPU rates.
hosted·ai’s 5× utilisation advantage
packet.ai runs on hosted·ai’s GPU pooling infrastructure, achieving up to 5× better hardware utilisation than static allocation. That efficiency flows through directly to lower per-token costs.
Last reviewed: 10 June 2026. Try Token Factory — first 10,000 tokens free →
Same models. Same API. Fraction of the cost. Start free — no credit card required.
Start Building →